

Navigating the Linguistic Labyrinth: The Interplay of AI, Language, and Thought

Understanding LLM and multimodal performance benchmarks
In the dynamic realm of artificial intelligence (AI), Multimodal Large Language Models (MLLMs) stand out as a potentially revolutionary development. With their exceptional precision, adaptability, and contextual awareness, they promise to reshape our understanding of AI capabilities.
Big Tech has been onto this trend for a while, with offerings such as Microsoft's Kosmos models (1 and 2), OpenAI's GPT-4, Google's PaLM 2 and Med-PaLM 2 and their upcoming Gemini model, and Meta's LLaMA models (which have been turned multimodal using the tokenization method to allow image inputs and video inputs). MLLMs, given their trajectory, are poised to be the dominant force in Gen AI in the coming years.
Traditional Large Language Models (LLMs) primarily focus on text-based applications. This specialization has revolutionized tasks like summarization, content creation and coding, but they are limited. MLLMs are designed to handle diverse data types and seamlessly integrate multiple data modalities. Their advantages over traditional LLMs include the following:
- Human-like Perception: MLLMs mirror how humans naturally process multisensory, often complementary, inputs. This design could make them more 'intelligent' than LLMs.
- Versatile User Experience: With multimodal input support, users can engage in more flexible and diverse interactions.
- Comprehensive Problem-Solving: Their multifaceted nature makes them adept at handling a wider range of tasks.
MLLMs capabilities will pave the way for diverse applications and personalized user experiences 🧠📊🌐
Using cutting-edge deep learning techniques and vast datasets, these models (depending on their architecture configuration, datasets and how they are trained) can potentially:
- Generate context-aware image captions
- Respond to combined text and image queries, and pave the way for text-to-image synthesis
- Convert speech to text with advanced precision
- Conduct cross-modality sentiment analysis
- Summarize videos by pinpointing intricate features
- Support video-integrated Q&A systems
Figure 1: Representation of multimodal models, source: Google
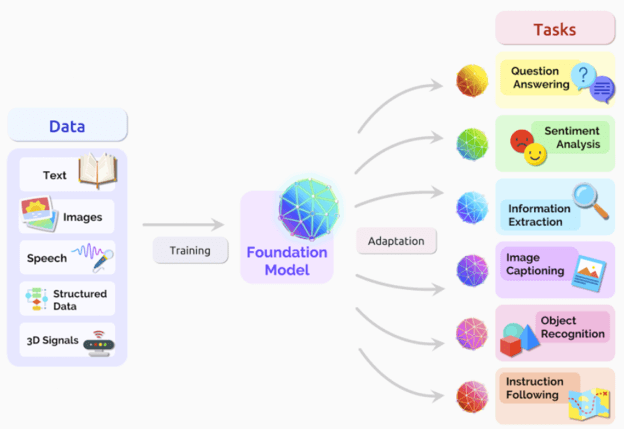
It is important to note that MLLMs deviate from traditional models by consolidating diverse data types into a unified encoding domain. Bringing input embeddings into the same space as the pre-trained transformer establishes a seamless connection, thus supporting efficient multitasking and data sharing across different end tasks (a consistent approach taken by several state-of-the-art models). Also, two machine learning techniques are usually applied to amplify their prowess: Representation Learning and Transfer Learning. The former aids models in forming a unified representation for all modalities, while the latter empowers them to learn core principles before specializing in specific areas.
What Challenges Await? 🌐
No advancement is without its challenges. Initial tests of MLLMs have shown Hallucinations (a recurrent, persistent issue across models). Challenges such as information leakage also emerge as we expand into the multimodal realm, and consideration must be given to implementing LLM debiasing strategies into the visual space (we may see a rise in data misinterpretations and there are some great blogs out there that discuss this).
A new Era of Multimodal Giants?💡
Google's Gemini, set to debut in December 2023, has the tech world abuzz. Speculated to be a Visual-Language-Action (VLA) model and a formidable rival to GPT-4, it could genuinely signal a seismic shift in AI.
For those wanting to learn more about MLLMs, Meta-Transformer also deserves a mention. This foundational model can process data from 12 different modalities, underlining the transformative potential of transformer architectures for cohesive multimodal intelligence. Meta-Transformer utilizes the same backbone to encode natural language, image, point cloud, audio, video, infrared, hyperspectral, X-ray, time-series, tabular, Inertial Measurement Unit (IMU), and graph data. It reveals the potential of transformer architectures for unified multimodal intelligence (it is a great place to start to understand the build and configuration of MLLMs).
Final Thoughts 💡
With the advances in MLLMs, we foresee a future where AI capitalizes on the interplay between diverse data modalities, heralding a significant shift in AI application and understanding. Interestingly, the importance of understanding the connections between various modalities will only continue to grow and so this should be an area of focus for developers. The upside will be a series of remarkable innovations and incredibly powerful applications, but it will demand rigorous exploration, validation, and iteration.
