
Evolution or Revolution: The Ascent of Multimodal Large Language Models

Controlling Costs in the Era of LLMs: A Strategic Approach for Developers, Project Managers, CIO and the CFO
Understanding LLM and multimodal model performance benchmarks
AI models are reshaping our world, making it imperative to gauge their capabilities accurately. This is where performance benchmarks come into play, serving as the yardsticks of AI competence, and helping consumers decide which model best suits their use case. In this blog, we summarize the benchmarks and how they help us understand and evaluate the diverse capabilities of AI models in text and multimodal contexts.
The tables below provide a structured overview of the various benchmarks used to evaluate different capabilities of AI models and were used in the recent evaluation of Google's Gemini models versus OpenAI's GPT-4.


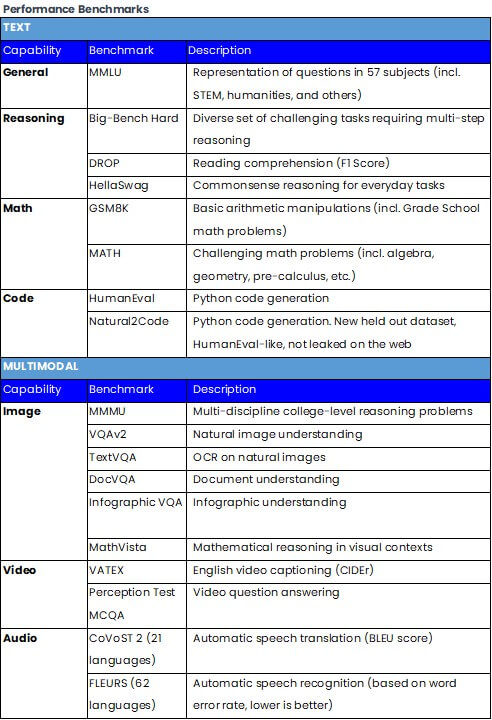
While Andrej Karpathy may only trust two LLM evals right now (Chatbot Arena and r/LocalLalma), we think this overview gives petty good insight for people when comparing models and making their selection.
.
