

The Dawn of GPT-5: Learning from GPT-4 and Embracing Sophistication

Understanding tokens and prompts is key for optimal LLMOps
A simple guide to understanding the architectural differences in models
Transformer models (such as BERT and GPT-3) have revolutionized the field of natural language processing (NLP). This is due to their capacity for parallelization (the ability to perform computations on multiple parts of the input data simultaneously), handling long-range dependencies (being able to consider and understand the relationship between elements in a sequence that are far apart), and their ability to scale, allowing LLMs to effectively train on and handle large amounts of data and information.
The Transformer is a type of neural network architecture which was introduced by Vaswani et al. (2017) in a paper titled "Attention is All You Need". A key feature of the Transformer architecture is that it uses the self-attention mechanism, which enables LLMs to focus on relevant parts of the input data while ignoring unnecessary information, improving contextually accurate responses and text generation. While the world of LLMs is moving fast and new architectures are emerging (such as the Receptance Weighted Key Value architecture), it is good to understand the architectural designs and categorizations of the encoder, decoder and encoder-decoder models. LLMs architectures and the pre-training objectives can differ significantly, and their configuration can determine where a model excels (for example, in text generation tasks, language understanding tasks, and understanding context) and where it has limitations.
Below is an updated Evolutionary Tree of Large Language Models (LLMs) split into three family branches (encoder-only, encoder-decoder, and decoder-only models). The Evolutionary Tree outlines the development of language models and the vast LLMs landscape and highlights LLM usage restrictions based on the model and data licensing information. The tree is based on the paper: Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond and efforts from @xinyadu, and has been modified by the tokes compare team to reflect some new LLMs (e.g., PaLM 2).
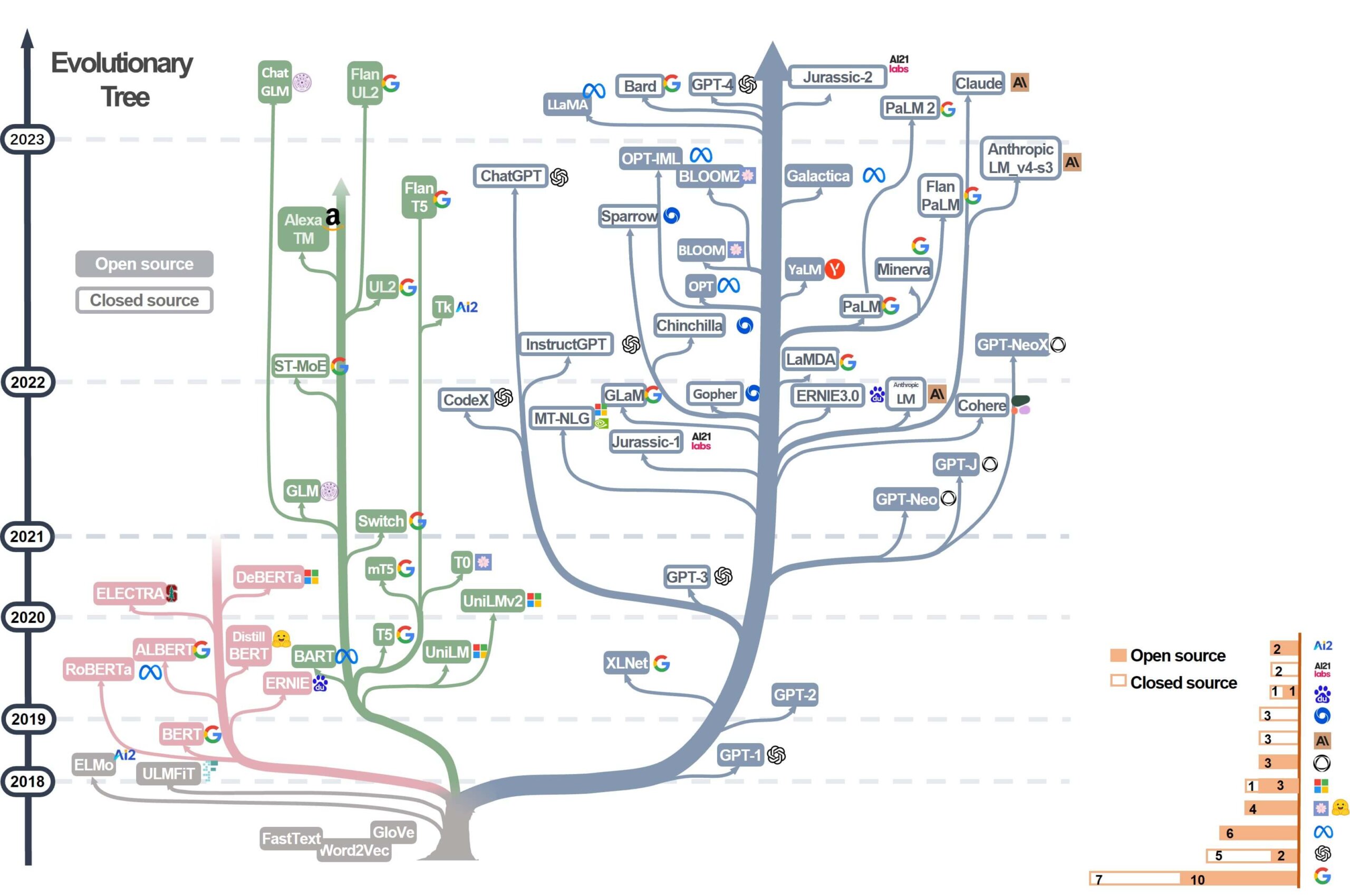
Understanding the differences between the three types of models (encoder, decoder and encoder-decoder models) is crucial for selecting the right model for the task, fine-tuning models for specific applications, managing computational resources, and guiding AI research and development. It is also worth mentioning that while these categorizations are helpful for understanding different types of models, many advanced LLMs often modify components and so this is not a strict categorization, but more of a conceptual one to understand the basics.
Encoder -
Only Models
- What is it?
An architecture that is optimized to understand the context of words in the input text but does not generate new text itself. - Overview
Encoder-only models take tokens (words, subwords, characters, or bytes) as inputs, process them through the encoder to produce a numerical representation (also known as feature vector or tensor) for each token, capturing the meaning and the context (bi-directional). This representation can be used in downstream tasks without further generation. - Strengths
Versatile for various tasks, including sequence classification, entity recognition, and extraction. Particularly excels in tasks requiring a deep understanding of the context, like sentiment analysis. Allows efficient parallel processing during training. - Limitations
Lacks the capacity to generate coherent text on its own. This limitation may make them less suitable for tasks involving text generation. - Examples
BERT, ELECTRA, RoBERTa - Where can I learn more?
Learn more: Access a video at Hugging Face's YouTube channel
Encoder -
Decoder Models
- What is it?
An architecture that both understands the context of words in the input text and generates new text. - Overview
Encoder-decoder models have two parts: the encoder takes tokens as inputs, converts them into numerical representations, and then the decoder uses these representations to generate an output sequence. These models are especially suitable for sequence-to-sequence tasks. - Strengths
Often the best performing models for tasks requiring both encoding and decoding, like machine translation and text summarization. However, these models can be computationally intensive and time-consuming to train and fine-tune. - Limitations
Due to the two-part design, encoder-decoder models can be slower to train and use more computational resources compared to encoder-only or decoder-only models. - Examples
FLAN UL2, FLAN T5 - Where can I learn more?
Learn more: Access a video at Hugging Face's YouTube channel
Decoder -
Only Models
- What is it?
An architecture that is optimized to generate new text based on the input.
- Overview
Decoder-only models also take tokens as inputs and convert them into numerical representations. However, unlike encoders, decoders use masked self-attention and focus on generating coherent sequences of text. They are often auto-regressive models (make predictions based on previous outputs of the model itself). - Strengths
Decoders excel at text generation tasks, such as storytelling and dialogue generation. Some of the most popular and widely used language models (e.g., GPT-4) are decoder-only models. - Limitations
Decoder-only models are slower to train because the prediction of each token depends on previous tokens, preventing parallel processing during training. Additionally, they may be less adept at tasks that require a deep understanding of the input sequence context without generating new text. - Examples
Bard, GPT-4, Jurassic-2, LLaMA, BLOOM, YaLM, Chinchilla, MT-NLG, PALM 2 - Where can I learn more?
Learn more: Access a video at Hugging Face's YouTube channel
